
Kas yra robots.txt? Kaip veikia?
Kas yra robots.txt?
Robots.txt failas – tai specialių instrukcijų rinkinys paieškos sistemų robotams (botams). Robots.txt failai dažniausiai skirti gerų robotų, pavyzdžiui “Google”, “Bing”, “Baidu”, veiklai valdyti, nes blogi robotai greičiausiai nesilaikys jokių nurodymų.
Kitaip tariant robots.txt failas yra tarsi ant sporto salės sienos pakabintas užrašas “Elgesio kodeksas”. Kuomet visi ateinantys “geri” lankytojai taisyklių laikysis, o “blogi” gali jas pažeisti ir dėl to bus išprašyti.
Kas yra bot’as?
Botas – tai automatizuota kompiuterinė programa, kuri sąveikauja su svetainėmis ir programine įranga (aplikacijomis). Botai kaip ir žmonės būna geri ir blogi. Vienas iš gerų botų tipų yra žiniatinklio naršyklės botas. Tokie botai “naršo” tinklalapius ir indeksuoja jų turinį, kad jis būtų rodomas paieškos sistemos rezultatuose. Robots.txt failas padeda valdyti šių žiniatinklio paieškos robotų veiklą, kad jie neapkrautų žiniatinklio serverio, kuriame talpinama svetainė, ir neindeksuotų puslapių, kurie nėra skirti viešam matymui.
Kaip veikia robots.txt failas?
Robots.txt failas yra tiesiog tekstinis failas be HTML žymėjimo kodo (todėl ir yra plėtinys .txt). Robots.txt failas talpinamas žiniatinklio serveryje kaip ir bet kuris kitas svetainės failas. Iš tikrųjų bet kurios konkrečios svetainės robots.txt failą paprastai galima peržiūrėti įvedus visą pagrindinio puslapio URL adresą ir pridėjus /robots.txt. Kaip pavyzdį įveskite https://seogenerolai.lt/robots.txt ir pamatysite jo turinį.
Į šį failą niekur kitur svetainėje nėra nuorodų, todėl vartotojai greičiausiai jo nepastebės, tačiau dauguma žiniatinklio naršyklės robotų, prieš pradėdami naršyti likusią svetainės dalį, pirmiausia ieškos šio failo.
Geras robotas, pavyzdžiui, “Google” žiniatinklio naršyklė arba naujienų kanalo robotas, prieš peržiūrėdamas kitus domeno puslapius, pirmiausia bandys aplankyti robots.txt failą ir laikysis jo nurodymų. Blogas robotas ignoruos robots.txt failą arba apdoros jį, kad rastų draudžiamus tinklalapius.
Tuo tarpu žiniatinklio naršyklės robotas laikysis konkrečiausių robots.txt faile pateiktų nurodymų. Jei faile yra vienas kitam prieštaraujančių nurodymų, robotas vykdys smulkesnį nurodymą.
Svarbu atkreipti dėmesį į tai, kad visiems subdomenams reikia atskiro robots.txt failo. Pavyzdžiui, nors https://seogenerolai.lt/ turi savo failą, visiems “Seogenerolai” subdomenams (blog.seogenerolai.lt, shop.seogenerolai.lt ir t. t.) taip pat reikia savo atskiro failo.
Kokie protokolai naudojami robots.txt faile?
Robots.txt failuose naudojami keli skirtingi protokolai. Pagrindinis protokolas vadinamas botų pašalinimo protokolu. Tai būdas nurodyti robotams, kurių tinklalapių ir išteklių vengti. Į robots.txt failą įtraukiami šiam protokolui suformatuoti nurodymai.
Kitas robots.txt failams naudojamas protokolas yra “Sitemap” protokolas. Jį galima laikyti robotų įtraukimo protokolu. Svetainių žemėlapiai parodo, kuriuos puslapius gali naršyti žiniatinklio naršyklė. Tai padeda užtikrinti, kad naršymo robotas (angl. crawler) nepraleis jokių svarbių puslapių.
Robots.txt failo pavyzdys
Žemiau yra pateiktas https://seogenerolai.lt/ robots.txt failo pavyzdys.
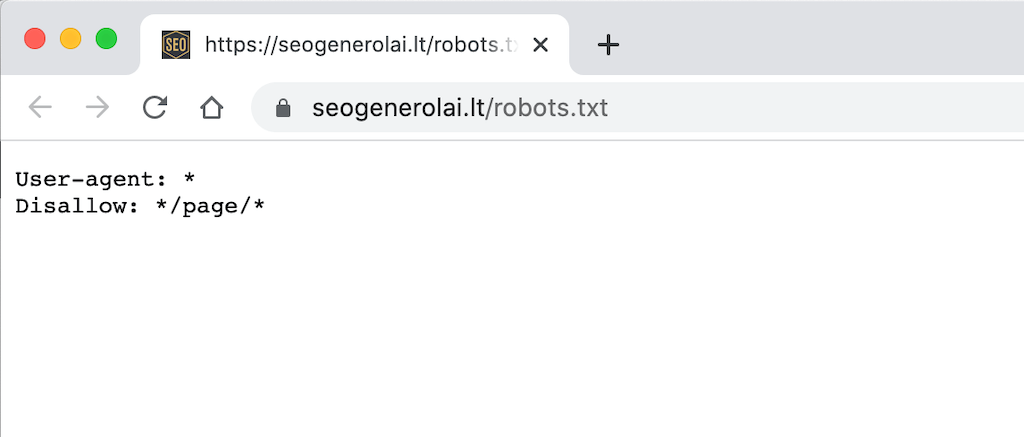
Kas yra naudotojo agentas? Ką reiškia: User-agent: *?
Bet kuris internete naršantis asmuo ar programa turi “naudotojo agentą” (angl. user agent) arba kitaip tariant priskirtą naršyklę, su kuria naršo. Kai žiniatinklyje naršo bet koks realus žmogus, tai apima tokią informaciją kaip naršyklės tipas ir operacinės sistemos versija, bet ne asmeninę žmogaus informaciją. Visa tai padeda svetainėms rodyti turinį, geriausiai suderinamą su naudotojo turima sistema (naršykle ir operacine sistema). Naudotojo agentas (teoriškai) padeda svetainės administratoriams sužinoti, kokie botai naršo svetainę. Bet faktiškai norint, galima apsimesti bet kokiu “user agent”.
Robots.txt faile svetainės administratoriai gali pateikti konkrečias instrukcijas konkretiems robotams, įrašydami skirtingas instrukcijas botų naudotojų agentams. Pavyzdžiui, jei administratorius nori, kad tam tikras puslapis būtų rodomas “Google” paieškos rezultatuose, bet ne “Bing” paieškos rezultatuose, į robots.txt failą jis gali įtraukti du komandų rinkinius: vieną rinkinį, prieš kurį rašoma “User-agent: Bingbot” ir vieną rinkinį, prieš kurį rašoma “User-agent: Googlebot”. Toliau jau seka konkrečios instrukcijos kas vienam paieškos sistemos botui yra leistina, o kas kitam draustina.
Pateiktame aukščiau pavyzdyje Seogenerolai įtraukė į robots.txt failą taisyklę User-agent: *. Žvaigždutės simbolis (“wild card”) prie naudotojo agento reiškia, kad nurodymai taikomi visiems robotams, o ne konkrečiam botui.
Kokie populiariausi paieškos sistemų naudotojo agentų pavadinimai?
Dažniausiai pasitaikantys paieškos sistemos boto naudotojo agento pavadinimai yra šie:
- Googlebot
- Googlebot-Image (paveikslėliams)
- Googlebot-News (naujienoms)
- Googlebot-Video (vaizdo įrašams)
Bing
- Bingbot
- MSNBot-Media (vaizdams ir vaizdo įrašams)
Baidu
- Baiduspider
Kaip robots.txt faile veikia “Disallow” komandos?
Komanda “Disallow” (uždraudimas) yra labiausiai paplitusi robotų pašalinimo protokole. Ji nurodo robotams neleisti pasiekti tinklalapio arba tinklalapių rinkinio, kuris yra po šios komandos. Neleistini puslapiai nebūtinai yra “paslėpti” – jie tiesiog nėra naudingi “Google” ar “Bing” vartotojui, todėl jiems nerodomi. Dažniausiai svetainės naudotojas vis tiek gali patekti į šiuos puslapius, jei žino, kur juos rasti.
Komandą “Disallow” galima naudoti įvairiais būdais. Keli iš jų parodyti žemiau pateiktame pavyzdyje.
Galima blokuoti vieną konkretų URL adresą.
Pavyzdžiui, jei “Seogenerolai” norėtų užblokuoti botus, kad jie negalėtų nuskaityti ir indeksuoti būtent šio įrašo (Kas yra robots.txt? Kaip jis veikia?), tokia komanda turėtų būti užrašyta taip:
Disallow: /izvalgos/robots-txt/Po komandos “disallow” įtraukiama tinklalapio URL dalis, kuri yra po pagrindinio puslapio – šiuo atveju https://seogenerolai.lt/. Įdiegus šią komandą, geri robotai negalės pasiekti tinklalapio https://seogenerolai.lt/izvalgos/robots-txt/, o puslapis nebus rodomas paieškos sistemų rezultatuose.
Galima blokuoti vieną katalogą
Kartais veiksmingiau blokuoti kelis puslapius iš karto, užuot juos visus išvardijus atskirai. Jei jie visi yra toje pačioje svetainės dalyje, robots.txt faile galima blokuoti tik tą katalogą, kuriame jie yra.
Pateiktas pavyzdys:
Disallow: /__izvalgos/Tai reiškia, kad visi __izvalgos kataloge esantys puslapiai neturėtų būti peržiūrimi paieškos robotų.
Kaip leisti pilną prieigą?
Tokia komanda atrodytų taip:
Disallow:Taip botams pranešama, kad jie gali naršyti visą svetainę, nes niekas nėra uždrausta.
Kaip paslėpti visą svetainę nuo bot’ų?
Disallow: /“/” čia reiškia svetainės hierarchijos “šaknį” arba puslapį, nuo kurio atsišakoja visi kiti puslapiai, taigi tai yra pagrindinis puslapis ir visi puslapiai, į kuriuos yra nuorodos. Naudojant šią komandą, paieškos sistemų robotai apskritai negali nuskaityti svetainės.
Kitaip tariant, vienas pasvirasis brūkšnys gali pašalinti visą svetainę iš interneto paieškos! Naudokite šią taisyklę labai atsakingai.
Kokios kitos komandos yra robotų pašalinimo protokolo dalis?
Allow: Kaip ir galima tikėtis, komanda “Leisti” nurodo, kad robotams leidžiama pasiekti tam tikrą tinklalapį ar katalogą. Ši komanda leidžia robotams pasiekti vieną konkretų tinklalapį, o kitiems faile esantiems tinklalapiams – ne. Ne visos paieškos sistemos pripažįsta šią komandą.
Crawl-delay: Komanda “crawl delay” skirta sustabdyti paieškos sistemų vorų botus nuo pernelyg didelio serverio apkrovimo. Ji leidžia administratoriams nurodyti, kiek laiko (milisekundėmis) robotas turėtų laukti tarp kiekvienos užklausos. Štai pavyzdys, kai komanda “Crawl-delay” turi laukti 5 milisekundes:
Crawl-delay: 5“Google” šios komandos neatpažįsta, nors kitos paieškos sistemos ją atpažįsta. “Google” administratoriai gali keisti svetainės naršymo dažnį “Google Search Console” paskyroje, bet tai daryti vertėtų tik išimtiniais atvejais.
Kas yra “Sitemap” protokolas? Kodėl jis įtrauktas į robots.txt?
Svetainės žemėlapis yra XML failas, kuris padeda robotams sužinoti, ką įtraukti į svetainės naršymą. Svarbu žinoti, kad nors “Sitemap” protokolas padeda užtikrinti, kad žiniatinklio voratinklio robotai nieko nepraleistų naršydami svetainę, robotai vis tiek vykdys įprastą naršymo procesą. Svetainių žemėlapiai nepriverčia naršymo robotų teikti skirtingą prioritetą tinklalapiams.
Kaip robots.txt susijęs su botų valdymu?
Norint užtikrinti, kad svetainė korektiškai veiktų, labai svarbu valdyti botus, nes net ir gera botų veikla gali pernelyg apkrauti serverį ir sulėtinti arba nutraukti interneto svetainės veikimą. Teisingai sudarytas robots.txt failas gerina bendrą svetainės SEO optimizaciją ir padeda kontroliuoti gerų botų veiklą.
Tačiau robots.txt failas nelabai padės valdant kenkėjišką botų srautą. Tam geriausiai tinka tokie kenkėjiškų botų valdymo sprendimai kaip pavyzdžiui: ” Cloudflare Bot Management” arba ” Super Bot Fight Mode”. Jie gali padėti pažaboti kenkėjišką botų veiklą nedarant poveikio svarbiausiems botams, pavyzdžiui, žiniatinklio naršyklėms “Google”, “Bing” ir kitoms.
Svarbiausios išvados (Key Takeaways)
- Robots.txt failas – tai specialių instrukcijų rinkinys paieškos sistemų robotams (botams).
- Robots.txt failas padeda valdyti populiariausių žiniatinklio paieškos robotų (“Google”, “Bing” ir kt.) veiklą, kad jie neapkrautų žiniatinklio serverio, kuriame talpinama svetainė, ir neindeksuotų puslapių, kurie nėra skirti viešam matymui.
- Į robots.txt failą visuomet verta įtraukti sitemap failo adresą.
- Teisingai sudarytas robots.txt failas gerina bendrą svetainės SEO optimizaciją ir padeda kontroliuoti gerų botų veiklą.
- Valdant kenkėjišką botų srautą geriausiai tinka tokie kenkėjiškų botų valdymo sprendimai kaip pavyzdžiui: ” Cloudflare Bot Management” arba ” Super Bot Fight Mode”.
Parengta pagal cloudflare.com informaciją.
Domina “SEO generolų” komandos teikiamos profesionalios SEO paslaugos ar konsultacijos? Užpildykite formą puslapio apačioje ir mes susisieksime su jumis artimiausiu metu.

